
Quick Start Guide
New to AI coding? Start here:
- Install Cursor (free tier available)
- Use GPT-5.2 for fast tasks, Claude Opus 4.5 for complex refactoring
- Learn the CRISP prompt framework
- Review all AI-generated code before committing
Already using AI tools? Jump to:
AI development tools have evolved from basic autocomplete into autonomous agents handling multi-file refactoring, reasoning, and automated testing. This guide covers selecting the right AI IDE, choosing optimal LLMs, and implementing agentic workflows without hallucinations or architectural drift.
TL;DR: AI-Augmented Development in 2026
- Best multi-file editor: Cursor - Composer mode, 8 parallel agents, RAG-optimized codebase awareness
- Best autonomous: AWS Kiro - Persistent multi-repo orchestration (9/10 autonomy)
- Best free tier: Google Antigravity - 5 parallel agents, access to Claude 4.5
- Best value: Windsurf - $15/mo for solid agentic flow
- Best coding models: Claude Opus 4.5 (80.9%) and GPT-5.2 (80%) lead on SWE-bench
- Best speed-to-quality: Gemini 3 Flash (78% SWE-bench, fastest inference)
- Largest context window: Gemini 3 Pro (1M tokens for large codebase analysis)
- Reality check: AI is a multiplier, not a replacement. Human supervision is required for architecture, security, and verifying stochastic outputs.
 Figure 1: The 2026 AI Editor Decision Tree - Which tool fits your project stack?
Figure 1: The 2026 AI Editor Decision Tree - Which tool fits your project stack?
AI Coding Deep Dives (This Series)
This guide is the overview. For hands-on, opinionated breakdowns of the tools and workflows below, read the companion articles:
- Antigravity vs Cursor vs Kiro vs Windsurf: Security Comparison — how the leading AI IDEs actually handle your code, secrets, and data.
- How I Built a $0 AI Coding Agency with Clawdbot — a real, first-person build using free-tier agents end to end.
- Vibe Coding to Production: Why 73% Fail — where AI-first workflows break down, and how to ship anyway.
- Why OpenAI Codex Drains Your Quota Too Fast — diagnosing and fixing runaway token usage.
- Pencil.dev: A Design Canvas That Lives in Your IDE — design-to-code without leaving your editor.
Part 1: AI Code Editors & IDEs
Cursor is an AI-first VS Code fork with agent mode for high-level goal execution. It uses RAG for deep context-awareness and LSP integration for codebase-wide refactoring.
Key Features (2026):
- Composer 2.0: Multi-file editing with parallel agents using Git worktrees
- RAG-Powered Context: Uses @References (@file, @Codebase) to pull the most relevant functions into the prompt window, optimizing token efficiency.
- BugBot: Automated PR reviewer with 1-click fixes
- YOLO Mode: Maximum autonomy for trusted codebases
Practical Verdict: Best for daily multi-file refactoring. Requires prompt engineering skills to prevent hallucination loops.
| Pros | Cons |
|---|---|
| Best multi-file editing | $20/mo (vs $10 Copilot) |
| Deep codebase awareness | Resource-heavy on large projects |
| Parallel agents | Learning curve for prompting |
| Model flexibility | Still needs code review |
Windsurf by Codeium is an AI-native IDE with Cascade agent for multi-file reasoning and proactive issue detection.
Key Features:
- Cascade Agent: Plans, edits, and self-iterates until the terminal command passes.
- Turbo Mode: Executes tasks with high autonomy, often resolving bugs in one pass.
- Local-First Memories: Remembers codebase patterns locally to ensure privacy and low-latency suggestions.
- MCP Integrations: Connects to GitHub, Slack, and Stripe to pull external data into the reasoning loop.
Practical Verdict: Excellent for large monorepos with high autonomy. Note: periodic quality regressions make it slightly less stable than Cursor.
| Mode | Autonomy | Best For |
|---|---|---|
| Chat Mode | Low | Explanations, debugging |
| Write Mode | Medium | Controlled generation |
| Turbo Mode | High | Full features, refactoring |
Kiro shifts from stochastic code generation to deterministic development by generating structured specs before writing code, ensuring AI output adheres to architectural constraints.
Key Features:
- Spec-Driven Architecture: AI generates a blueprint, gets approval, then executes
- Multi-Repo Persistence: Handles 15+ repositories in a single session
- AWS Native: Direct Bedrock integration; data stays in your VPC
- Variable Precision: Haiku 4.5 for fast tasks, Opus 4.5 for reasoning
Practical Verdict: Industry leader for multi-day autonomous tasks and multi-repo orchestration. Best for complex backend infrastructure requiring deterministic outputs.
Google Antigravity is Google DeepMind’s agent-first IDE, offering high-end LLM power (Gemini 3 Pro) for free.
Key Features:
- Mission Control: Orchestrates 5 specialized agents across different stack layers
- Multimodal Validation: Browser Agent visually verifies design-to-code fidelity
- Zero-Credit Completions: Local models handle basic completions, reserving cloud for complex reasoning
Practical Verdict: Best free tier in 2026 with access to Claude Opus 4.5 and Gemini 3 Pro. Steep learning curve but high potential for greenfield projects.
GitHub Copilot: Universal IDE Support
GitHub Copilot has universal IDE support - VS Code, Visual Studio, JetBrains, Vim, and Neovim.
Key Features:
- Copilot Chat: Integrated conversational AI
- Copilot Workspace (Beta): Plan features from natural language
- Enterprise Security: IP indemnification, data privacy
Best For: Teams that can’t switch IDEs or need enterprise compliance.
Quick Comparison: AI Code Editors
| Feature | Cursor | Windsurf | Antigravity | Kiro | Copilot |
|---|---|---|---|---|---|
| Stability | ✅ Solid | ⚠️ Variable | ⚠️ New | ✅ Engineering Grade | ✅ Solid |
| Autonomous tasks | ✅ Agent | ✅ Turbo | ✅ Native | ✅ Industry Lead | ⚠️ Workspace |
| IDE support | VS Code fork | VS Code fork | Standalone | VS Code fork | All major |
For a deeper security-focused analysis of how these editors handle your code and data, see our detailed security comparison of Antigravity, Cursor, Kiro, and Windsurf.
AI Code Editor Pricing (as of March 2026, verify current pricing)
| Tool | Free Tier | Pro Tier | Enterprise/Max |
|---|---|---|---|
| Cursor | 2000 code completions | $20 (Unlimited tab) | $200 (20x usage) |
| Windsurf | 25 prompt credits | $15 (500 credits) | $30/user (Teams) |
| Kiro | 50 credits (No Opus) | $20 (1,000 credits) | $200 (10,000 credits) |
| Antigravity | Public Preview (Free) | Incl. Google One | Incl. Workspace AI |
| Copilot | N/A | $10/mo | $39/user (Enterprise) |
Feature Comparison by Pricing Tier
| Price Point | Best Value | What You Get |
|---|---|---|
| Free | Antigravity | 5 parallel agents, Claude 4.5, Gemini 3 Pro |
| $10-15/mo | Windsurf ($15) | 500 credits, Cascade agent, solid autonomy |
| $20/mo | Cursor | Unlimited completions, 8 parallel agents, best stability |
| Enterprise | Kiro ($200) | 10,000 credits, multi-repo orchestration, AWS integration |
Autonomous Coding Agent Ratings (2026)
Note: These ratings reflect my personal experience testing these tools in production environments. Your results may vary based on project complexity and workflow.
| Tool | Autonomy Rating | Strengths | Weaknesses |
|---|---|---|---|
| Kiro | 9/10 | Persistent operation, multi-repo, specs | Standalone platform, steeper curve |
| Cursor Agent | 8.5/10 | Long-running projects, browser build | Privacy concerns, more check-ins |
| Antigravity | 8/10 | 5 parallel agents, mission control | Session-based, merge conflicts |
| Windsurf Cascade | 7/10 | IDE-native, proactive, great UI | Slower execution, shorter sessions |
Part 2: Understanding the Core Technology
Retrieval-Augmented Generation (RAG)
AI code editors use RAG to index your codebase into vectors and retrieve only the most relevant snippets for your prompt. This prevents context overflow and reduces API costs.
Why this matters: Hallucinations usually indicate retrieval failure. Fix by explicitly @-referring to missing files.
Example:
❌ "Update the auth logic"
✅ "Update the auth logic in @auth-service.ts and @middleware/auth.ts"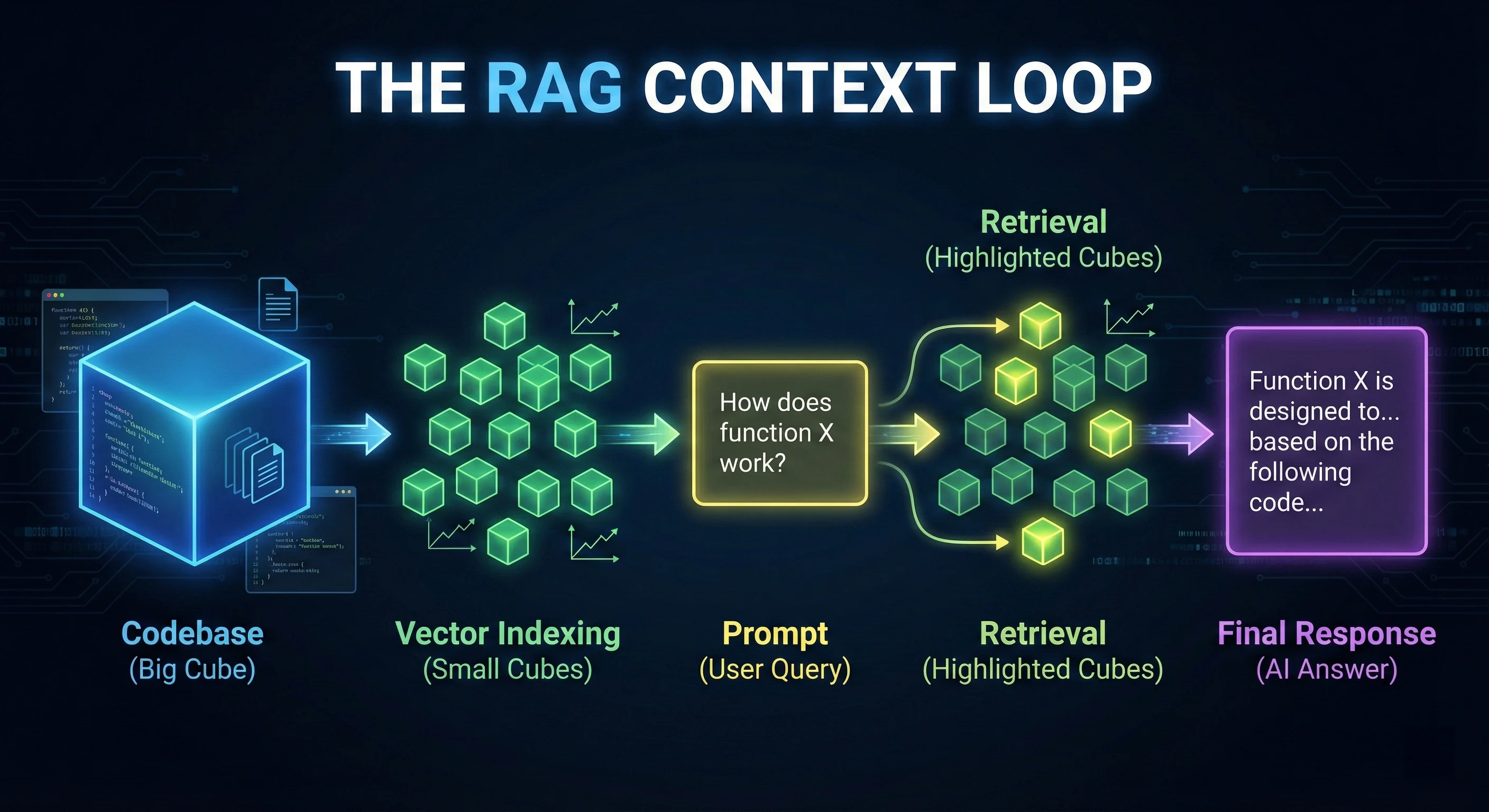 Figure 2: The RAG Context Loop - How agentic IDEs index and retrieve your codebase context.
Figure 2: The RAG Context Loop - How agentic IDEs index and retrieve your codebase context.
Context Windows: Why Size Matters
A context window is the maximum text (tokens) an AI can process in a single interaction. Claude Opus 4.5’s 200K tokens allows it to hold entire architectural patterns for multi-file refactoring.
Understanding this prevents context overflow where the model “forgets” earlier instructions.
| Model | Context Window | Best For |
|---|---|---|
| GPT-4o | 128K tokens | Component-level refactoring |
| Claude Opus 4.5 | 200K tokens (1M beta) | System-level architecture |
| GPT-5.2 | 400K tokens | Multi-repo orchestration |
| Gemini 3 Pro | 1M tokens | Entire codebase analysis |
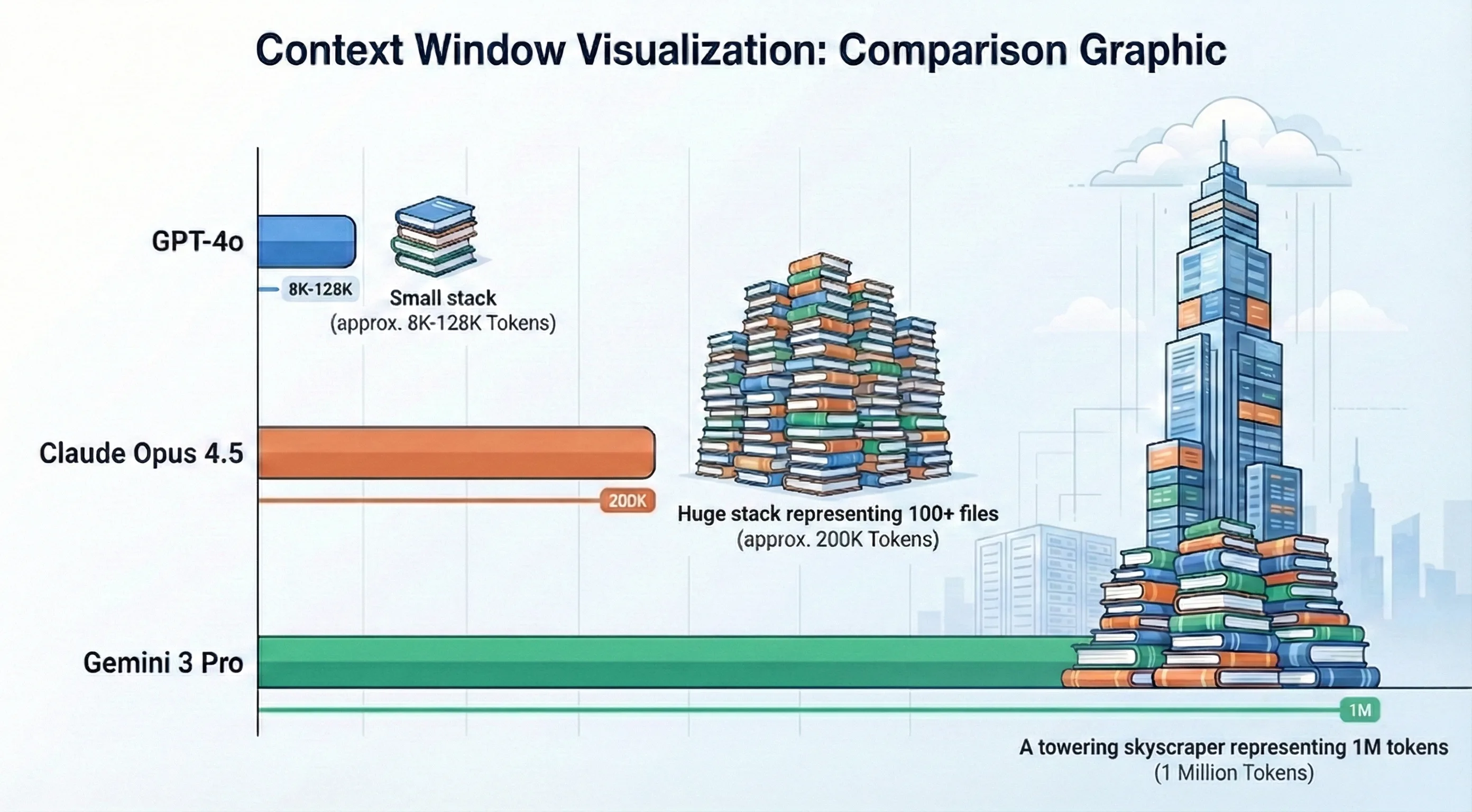 Figure 3: Context Window Comparison - Visualizing the reasoning capacity of 2026 LLMs.
Figure 3: Context Window Comparison - Visualizing the reasoning capacity of 2026 LLMs.
Local-First Inference and Privacy
For enterprise teams with strict data policies, Continue and Tabby allow local model deployment via Ollama or Llama.cpp.
Benefits: Privacy (code never leaves your machine), zero network latency, unlimited tokens
Requirements: M3 Max or RTX 4090 recommended, 32GB+ RAM, expect 30-50% lower quality vs cloud
Stochasticity vs. Determinism
LLMs are stochastic - they predict tokens based on probability, causing hallucinations. The same prompt can produce different outputs.
Kiro’s solution: Force a deterministic spec first. Verify the logic chain before code is written. Similarly, TypeScript’s type system acts as a guardrail that constrains AI output to valid types.
Part 3: Latest LLM Models for Coding
Note: Model versions and benchmarks evolve rapidly. The versions listed below (GPT-5.2, Claude Opus 4.5, Gemini 3) were current as of March 2026. Always verify the latest model versions and capabilities on each provider’s official documentation.
GPT-5 Series (OpenAI)
GPT-5 launched August 2025 with updates in November (5.1) and December (5.2).
GPT-5.2 (December 2025):
- Context Window: 400K tokens
- SWE-bench: 80%
- Adaptive Modes: “Instant” for simple queries, “Thinking” for complex workflows
- Best For: Multi-step agentic tasks, complex refactoring
GPT-5.1 (November 2025):
- SWE-bench: 76.3%
- Best For: Fast pair programming, speed-critical tasks
Claude 4.5 Series (Anthropic)
Claude Opus 4.5 (November 2025):
- Context Window: 200K tokens (1M beta)
- Best For: Long-form content, sensitive code, architectural planning
- Strength: Superior multi-file reasoning, powers Claude Code CLI
Claude Sonnet 4.5: Speed-quality balance for daily coding and agents.
Claude Code CLI:
npm install -g @anthropic-ai/claude-code
claude-code "Refactor the auth module to use JWT tokens.
Update all affected tests and regenerate API docs."Claude Code reads files, runs commands, edits code, and iterates autonomously in your terminal. For a practical example of building an entire AI coding agency using Claude’s agentic capabilities, see how I built a $0 AI coding agency with ClawdBot.
Gemini 3 Series (Google)
Launched November 2025, Gemini 3 powers Google Antigravity IDE.
| Model | Best For | Key Feature |
|---|---|---|
| Gemini 3 Pro | Complex tasks, multimodal | Extended thinking toggle |
| Gemini 3 Flash | Speed-critical tasks | Fastest inference |
| Gemini 3 Deep Think | Algorithmic problems | Mathematical reasoning |
Best For: Google Workspace integration, multimodal workflows (images → code), video-to-code generation.
Understanding Benchmarks
SWE-bench Verified is the industry-standard benchmark measuring AI models solving real GitHub issues across 500 verified software engineering problems. A score of 80% means 400 of 500 bugs resolved without human intervention.
LLM Comparison for Coding
| Model | SWE-bench | Context | Best For | Speed |
|---|---|---|---|---|
| Claude Opus 4.5 | 80.9% | 200K (1M beta) | Best reasoning, sensitive code | Slow |
| GPT-5.2 | 80% | 400K | Adaptive reasoning modes | Medium |
| Gemini 3 Flash | 78% | 1M | Best speed-to-quality ratio | Very Fast |
| GPT-5.1 | 76.3% | 400K | Fast pair programming | Fast |
| Gemini 3 Pro | 76.2% | 1M | Google ecosystem, multimodal | Medium |
| Claude Sonnet 4.5 | 70.5% | 200K | Daily coding, agents | Fast |
Part 4: No-Code/Low-Code AI Builders
No-code builders generate full applications from natural language. Ideal for MVPs, prototypes, and validating ideas.
v0 by Vercel: Best for UI Generation
v0 builds agents, apps, and websites with design mode, GitHub sync, and one-click Vercel deployment.
Key Features:
- UI Generation: React + Next.js + Tailwind + shadcn/ui from prompts or images
- Design Mode: Visual iteration on generated components
- Agentic by Default: Automatic database and API integration
Best For: Rapid UI scaffolding, marketing sites, dashboards. Limitation: Frontend-focused - lacks built-in backend.
Lovable: Fastest Full-Stack MVPs
Lovable generates full-stack web apps (React + Tailwind + Supabase) from natural language.
Key Features:
- Full-Stack: React + TypeScript + Tailwind + Vite + Supabase
- Speed: MVP in ~12 minutes
- Editable Code: Real code synced to GitHub
Practical Verdict: Better design quality than Bolt.new out of the box. Burns credits fast; manual cleanup often needed for production.
Best For: Non-technical founders, quick demos, landing pages with backend.
Bolt.new: Browser-Based Full-Stack
Bolt.new is a browser-based full-stack generator with zero setup.
Key Features:
- Browser IDE: No local setup
- Framework Agnostic: React, Vue, Next.js, Astro, Svelte, React Native
- Code Export: Download or sync to GitHub
Practical Verdict: Excellent for quick prototypes with real code export. Watch for token burn - AI sometimes reverts manual changes.
Best For: Quick prototyping, testing ideas, browser-based development.
Replit: Full Cloud IDE
Replit offers rapid prototyping with full control, AI integration via Ghostwriter/Replit Agent, and team collaboration.
When to Use Replit over Lovable/Bolt.new:
- Production-grade versioning and stability
- Complex backend logic beyond Supabase
- Team scalability, 50+ language support
Practical Verdict: Use Lovable for fast idea validation; switch to Replit for production infrastructure.
Anything: Mobile App Builder
Anything is an AI builder for iOS/Android with one-click App Store deployment.
Key Features:
- Mobile Native: iOS and Android from natural language
- Large Projects: Auto-refactoring for >100k LOC
- One-Click Deploy: Ship to App Store instantly
- Asset Generation: Creates images, icons, and assets
Best For: Mobile apps, cross-platform products, App Store presence. Limitation: Newer platform with fewer community resources.
Base44: SaaS Builder with Payments
Base44 generates full SaaS apps with built-in backend, database, payments, and auth.
Key Features:
- Full SaaS Stack: Frontend + backend + database + auth + Stripe
- Instant Hosting: Apps deployed immediately
- Integrations: Gmail, Slack, Stripe, Google Calendar
- White-Label: Custom branding and domains
Pricing: Free tier available; paid from $16/mo (billed annually)
Best For: SaaS MVPs, internal tools, apps needing payments/auth out of the box.
No-Code Builder Comparison
| Feature | v0 | Lovable | Bolt.new | Anything | Base44 | Replit |
|---|---|---|---|---|---|---|
| Best For | UI components | Full-stack MVP | Prototypes | Mobile apps | SaaS apps | Production |
| Mobile | ❌ | ❌ | ⚠️ Expo | ✅ Native | ❌ | ⚠️ |
| Backend | ❌ | ✅ Supabase | ✅ Basic | ✅ | ✅ Built-in | ✅ Full |
| Payments | ❌ | ✅ Stripe | ❌ | ✅ Stripe | ✅ Stripe | ⚠️ Manual |
| Large Projects | ⚠️ | ⚠️ | ❌ | ✅ 100k+ LOC | ⚠️ | ✅ |
| Non-Dev Friendly | ✅ | ✅ Best | ⚠️ | ✅ | ✅ | ❌ |
Part 5: Specialized AI Tools
Devin: Autonomous AI Software Engineer
Devin by Cognition Labs handles entire projects from planning through deployment.
Reality Check (March 2026):
- ~15% success rate on complex tasks (independent testing)
- Official SWE-bench: 13.86% unassisted
- Struggles with vague/complex architectural decisions
- Excels at repetitive tasks: migrations, refactoring, bug fixing
- By late 2025: 67% PR merge rate, 4x faster on defined tasks
Cost: ~$500/month team tier
Open-Source Alternatives
For privacy, customization, and cost control:
| Tool | Type | Best For |
|---|---|---|
| Aider | Terminal pair programmer | Git integration, multi-file editing |
| Continue | IDE extension | Model flexibility, local LLMs |
| Tabnine | Enterprise completions | Privacy-focused, on-premise |
| Tabby | Self-hosted assistant | Full privacy, customization |
AI Code Review Tools
AI is transforming PR review. These tools integrate with GitHub for automated, context-aware code reviews.
CodeRabbit
CodeRabbit provides automated PR reviews with line-by-line suggestions and security detection.
Key Features:
- Continuous Reviews: Incremental on each commit
- Blazing Fast: ~5 seconds
- 35+ Linters: Integrates static analysis
- MCP Integration: Pulls docs and project context
Catches issues often missed in manual review - especially security vulnerabilities and cross-file logic flaws.
Greptile
Greptile builds a “codebase knowledge graph” using AST parsing for semantic understanding.
Key Features:
- Knowledge Graph: Maps function calls, inheritance, dependencies
- 3x Bug Detection: Higher catch rates than competitors
- Jira/Notion Integration: Understands context behind changes
The most “intelligent” reviewer tested - catches issues requiring understanding how the codebase fits together.
Cursor AI Features
Cursor provides built-in code review for paid users.
Key Features:
- Diff Analysis: Reviews changes using Cursor’s AI
- 1-Click Fixes: Apply fixes directly
- Free for Paid Users: Included with Pro/Pro+/Ultra
Integrated workflow if you’re already on Cursor. For teams not on Cursor, CodeRabbit or Greptile offer more flexibility.
Code Review Tools Comparison
| Feature | CodeRabbit | Greptile | Cursor BugBot |
|---|---|---|---|
| Best For | Fast PR reviews | Deep codebase understanding | Cursor users |
| Speed | ✅ ~5 seconds | ⚠️ Slower (deeper analysis) | ✅ Fast |
| Codebase Context | ✅ Good | ✅ Best (knowledge graph) | ⚠️ Diff-focused |
| Integrations | ✅ GitHub, GitLab, MCP | ✅ GitHub, Jira, Notion | ⚠️ GitHub only |
| Price | Free tier + paid | Free tier + paid | Included with Cursor |
Part 6: The CRISP Prompt Engineering Framework
Effective prompts are the difference between AI that helps and AI that wastes time.
CRISP Components
- Context: Relevant files, errors, constraints
- Role: Perspective to take
- Intent: What you’re trying to accomplish
- Specifics: Tech stack, patterns, naming
- Preferences: Style, error handling, edge cases
This moves from basic zero-shot prompting to structured prompting that often matches few-shot effectiveness.
Real-World CRISP Examples
Example 1: Component Creation
❌ Vague prompt:
Create a table component✅ CRISP prompt:
Context: React 19 app using @components/ui/Button.tsx patterns
Role: Senior React developer valuing accessibility and performance
Intent: Create a sortable data table for user records with pagination
Specifics: TypeScript generics, TanStack Table v9, design tokens from @tokens.css
Preferences: Keyboard navigation, ARIA labels, virtualization for 1000+ rowsExample 2: Authentication Refactoring
❌ Vague prompt:
Fix the auth system✅ CRISP prompt:
Context: @auth-module.ts currently uses JWT in localStorage (security risk)
Role: Senior Security Engineer
Intent: Migrate to HTTP-only cookies with refresh token rotation
Specifics: Node.js 22, Express 5.0, Redis for token storage, 15min access / 7day refresh
Preferences: Include middleware tests, update Swagger docs, add rate limitingExample 3: Performance Optimization
❌ Vague prompt:
Make this faster✅ CRISP prompt:
Context: @UserDashboard.tsx renders 500+ items, causing 3s load time
Role: Performance engineer focused on Core Web Vitals
Intent: Reduce initial render to <1s while maintaining UX
Specifics: React 19, already using React.memo, need virtualization
Preferences: Use react-window, lazy load images, maintain scroll positionPart 7: MCP - Model Context Protocol
MCP separates good AI workflows from great ones. It lets AI assistants connect to external data sources beyond pasted files.
Supported By
- Cursor ✅
- Kiro ✅
- Claude Desktop ✅
- Windsurf (limited)
Available MCP Servers
| MCP Server | Use Case |
|---|---|
| Figma | Design-to-code workflows |
| PostgreSQL | Database schema context |
| GitHub | Issue and PR context |
| Slack | Team discussion context |
| Stripe | Payment API context |
The Figma MCP integration is particularly powerful for design engineers who need to maintain consistency between design systems and code implementations.
Setting Up Figma MCP
npm install -g @anthropic/mcp-server-figmaConfigure Claude Desktop (~/Library/Application Support/Claude/claude_desktop_config.json):
{
"mcpServers": {
"figma": {
"command": "mcp-server-figma",
"env": {
"FIGMA_ACCESS_TOKEN": "your-token"
}
}
}
}Part 8: Common Pitfalls
Pitfall 1: Accepting Without Reviewing
AI-generated code often looks correct but misses critical details. Always review for security, error handling, and edge cases.
Example: Form Submission
// ❌ AI generated - missing auth, error handling, headers
const handleSubmit = async (data: FormData) => {
await fetch("/api/users", { method: "POST", body: JSON.stringify(data) });
};
// ✅ After review - added auth, error handling, proper headers
const handleSubmit = async (data: FormData) => {
const response = await fetch("/api/users", {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${token}`,
},
body: JSON.stringify(data),
});
if (!response.ok) {
throw new Error(`Failed to create user: ${response.statusText}`);
}
return response.json();
};Example: Database Query
// ❌ AI generated - SQL injection vulnerability
const getUser = async (userId: string) => {
return db.query(`SELECT * FROM users WHERE id = ${userId}`);
};
// ✅ After review - parameterized query prevents SQL injection
const getUser = async (userId: string) => {
return db.query("SELECT * FROM users WHERE id = $1", [userId]);
};Security vulnerabilities like SQL injection are common in AI-generated code. Using TypeScript with proper type definitions helps catch many of these issues at compile time, but manual security review is still essential.
Example: React Component
// ❌ AI generated - missing accessibility, key prop, loading state
const UserList = ({ users }) => (
<ul>
{users.map((user) => (
<li>{user.name}</li>
))}
</ul>
);
// ✅ After review - added accessibility, keys, loading/error states
const UserList = ({ users, loading, error }) => {
if (loading) return <div role="status">Loading users...</div>;
if (error) return <div role="alert">Error: {error.message}</div>;
if (!users.length) return <p>No users found</p>;
return (
<ul aria-label="User list">
{users.map((user) => (
<li key={user.id}>{user.name}</li>
))}
</ul>
);
};AI-generated components often miss critical accessibility patterns and proper error handling. Always verify ARIA attributes, keyboard navigation, and loading states before shipping to production.
Pitfall 2: Wrong Tool for the Job
| Task | Wrong Tool | Right Tool |
|---|---|---|
| Simple autocomplete | Claude Opus 4.5 (expensive) | Gemini 3 Flash, Copilot |
| Multi-file refactor | ChatGPT (no codebase context) | Cursor Composer |
| UI prototype | Cursor (overkill) | v0, Lovable |
| Production app | Lovable (limited) | Replit, Cursor |
Choosing the right tool significantly impacts productivity. For React applications, understanding modern state management patterns helps you architect AI-generated code that scales properly from prototype to production.
Pitfall 3: Expecting Too Much from “Autonomous” Tools
Reality Check: Tools marketed as fully autonomous (e.g., Devin) currently complete only about 15% of complex architectural requests without human intervention. They still require heavy supervision.
All AI tools require:
- Clear, specific prompts
- Human review of output
- Architecture decisions by humans
- Security verification
Part 9: The Future: Vibe Coding & Agentic Autonomy
As we move through 2026, the term “Coding” is being replaced by “Vibe Coding.” This isn’t just a meme; it represents a fundamental shift in how we interact with machines.
Actionable Workflow: From Autocomplete to Intent
- Shift to Intent-Based Prompting: Stop writing line-by-line instructions. Describe the architectural outcome and let tools like Antigravity or Claude Code suggest the implementation.
- Act as a Systems Orchestrator: Your primary role is no longer typing syntax but validating system boundaries, security, and logic.
Actionable Workflow: Managing Multi-Agent Systems
- Delegate Specialized Tasks: Leverage parallel agents in tools like Cursor’s Composer (which supports up to 8 parallel agents).
- Automate Peripherals: Assign agents to write tests, handle documentation, and run security checks while you focus on core application logic.
Actionable Workflow: Thriving as a Modern Developer
- Master the Spec: Learn to write clear, deterministic specifications before allowing AI to generate code.
- Verify with Precision: Always manually review AI output to catch the 15% of complex tasks it still gets wrong.
- Bridge the Prototype-to-Production Gap: Avoid the trap where 73% of vibe-coded projects fail to reach production by applying rigorous engineering practices (testing, CI/CD, code review) after initial AI generation.
Key Takeaways
- Cursor leads for daily workflow - RAG-optimized Composer mode handles 90% of multi-file tasks with parallel agent support
- Kiro excels at autonomy - Spec-driven architecture enables complex, multi-repo infrastructure work with minimal supervision
- Antigravity offers best value - Generous free tier with parallel agents and access to top models (Claude 4.5, Gemini 3 Pro)
- Claude Opus 4.5 leads benchmarks - 80.9% SWE-bench score with 200K context window for superior reasoning on complex tasks
- Prompting is the new skill - CRISP framework mastery differentiates effective orchestration from frustrating hallucinations
- AI review catches more bugs - CodeRabbit and Greptile detect 30% more logic errors than manual review alone
- Local LLMs ensure privacy - Continue + Ollama provides enterprise compliance without sacrificing development speed
- Always review AI output - Current tools require human verification for security, architecture, and edge cases
Ready to start? Build your first agentic workflow using Cursor today by downloading the editor, connecting your preferred LLM, and applying the CRISP framework to your next refactoring task!
Recommended Video Resources
Related Resources
- The Design Engineer’s Guide - How to bridge designs to code with AI.
- TypeScript Patterns - Why strong types prevent 40% of AI hallucinations.
- React Performance Optimization - Using AI to identify rerender bottlenecks.